每天都有大量的车流在城市内、城际间来往穿梭,产生海量的运行数据。轨迹数据就是这些海量数据中的一类,它描述了车辆等各类交通参与物在特定交通环境下的行驶轨迹。
轨迹数据集在交通环境建模、智能汽车开发、驾驶行为分析等方面具有重大意义。目前在国际上有较大影响力的两个轨迹数据集是NGSIM和HighD:
◆NGSIM:2004年发布于美国,描述的是城市快速路中的车辆轨迹信息。记录时长1.5小时,单向车道数5-6条,记录距离500-640米,车辆数9206辆(包括小轿车数量8860辆,卡车数量278辆),累计驾驶距离5071千米,累计驾驶时长147小时。
◆HighD:2018年发布于德国,描述的是高速直道中的车辆轨迹信息。记录时长16.5小时,单向车道数2-3条,记录距离400-420米,车辆数110000辆(包括小轿车数量90000辆,卡车数量20000辆),驾驶累计距离45000千米,驾驶累计时长447小时。
这两个轨迹集被广泛应用于智能驾驶、交通模拟等多个领域的模型开发与验证工作,主要包括微观交通模型构建、车辆运动轨迹预测、驾驶员意图识别、驾驶行为模仿学习、自动驾驶决策规划等等。
研究成果大量发表在诸如IV,ITSC,IROS,CVPR等智能汽车和计算机领域的高水平国际学术会议上。
由于国内外交通环境、交通法规、驾驶行为等差异,国外的轨迹数据集不能完全体现中国道路与驾驶特征。
清华大学苏州汽车研究院和江苏智能网联汽车创新中心致力于建设中国特色轨迹数据集,从真实道路交通数据中提取各类车辆、行人等轨迹信息,构建了包含多种道路类型的轨迹数据集 Mirror-Traffic。
Mirror-Traffic是江苏省智能网联汽车创新中心自主研发的场景库“镜(Mirror)”的组成部分,也是场景库“镜(Mirror)”的数据基础,目前“镜(Mirror)”已公开部分典型场景,后续我们将会陆续推出更多“镜(Mirror)”系列产品。
Mirror-Traffic运用图像识别与追踪技术对真实道路图像中的交通参与物进行识别与跟踪,并对提取后的轨迹进行过滤与筛选,最终得到轨迹数据集。
Mirror-Traffic具备以下特点:
1.覆盖多种道路类型(匝道、直道、弯道、十字路口等)
2.多种交通流状态(车流量小、适中、拥堵等)
3.数据中包含多种车辆类型和行人等
4.交通参与物轨迹精度可以达到厘米级
5.数据来源于真实道路场景
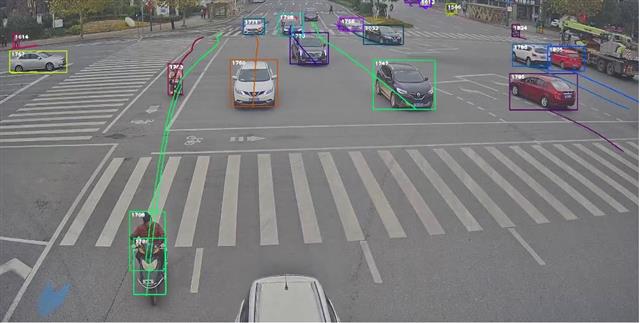
对交通参与物进行识别、跟踪
由于匝道口处存在大量变道需求,且道路曲率较大,交通事故易发,故成为了自动驾驶研究重点关注的道路类型。本次专门针对进、出匝道的场景,发布匝道处的车辆交互轨迹数据集。
本次公开的三个数据集,分别是某市同一条高速公路的汇入匝道和汇出匝道,以及某市城市快速路汇入匝道的真实轨迹数据。
三个轨迹集累计行驶里程254.5千米,累计行驶时长3.6小时,累计行驶车辆1827辆,累计变道数量577次,累计合流数量237次,累计分流数量290次。
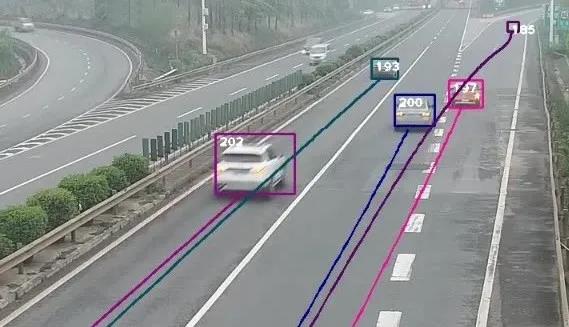
匝道处场景
1. 驾驶场景提取
2. 驾驶场景生成
3. 驾驶行为、意图预测类模型研发
4. 自然驾驶行为的模仿学习
5. 人类行为的分析与模仿
6. 自动驾驶预测和规划算法的开发和验证
7. 交通流(速度、密度)分析
8. 微观交通模型仿真
举例:我们从轨迹集中提取了真实的匝道汇入场景,并通过51sim-one仿真软件复现,如下图合流汇入场景:
匝道汇入场景作为一种功能场景,我们可以通过对大量匝道汇入轨迹的统计分析,得到更细分的逻辑场景类别以及场景关键参数的统计分布情况。接着,我们就可以从分布中采样来泛化出更多的具体场景。这是自动驾驶汽车基于场景验证的一般思路。
但上述方法得到的测试场景,都是提前为自动驾驶测试车生成好的确定性场景(deterministic scenario)。换句话说,不管我们测试车做出何种决策,场景中的其他道路使用者的运动并不会受到影响,这显然与自动驾驶汽车上路时需要面对真实人类驾驶员有很大的区别。为此,我们创建交互式场景来为自动驾驶汽车还原更加真实的“对手”。
交互式场景的核心应是具有人类行为的智能体的构建。我们基于真实交通数据,运用主流的机器学习算法,并考虑交通规则、地域差异等约束来持续地训练我们的类人交通智能体,他们可以实现与自动驾驶汽车间的动态交互,用于模拟更加真实的交通环境。
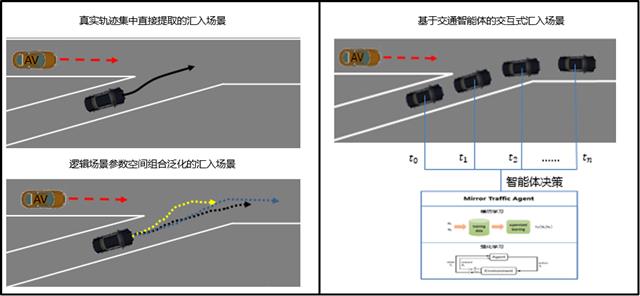
匝道汇入测试场景生成


